Observability สำหรับงานเว็บ: ใช้ Logs, Metrics และ Traces แก้ปัญหาได้ตรงจุด
เมื่อเว็บไซต์ช้าหรือเกิดปัญหา สาเหตุมักไม่ได้มาจากบั๊กเพียงจุดเดียว แต่เป็นผลจากหลายเหตุการณ์ที่เชื่อมโยงกัน Observability ช่วยให้ทีมมองเห็นสิ่งที่เกิดขึ้นจริงในระบบผ่าน 3 เสาหลักคือ Logs, Metrics และ Traces เพื่อวิเคราะ
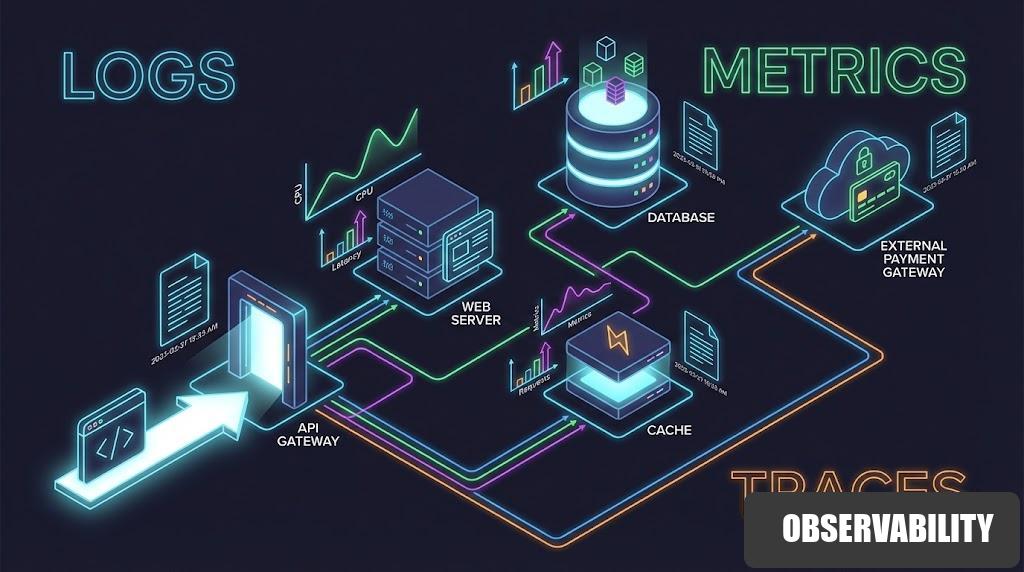
Observability สำหรับงานเว็บ: มองระบบให้เห็นก่อนจะแก้ได้ไว
การทำเว็บไซต์หรือระบบออนไลน์ในปัจจุบันไม่ได้ยากแค่เรื่องการเขียนโค้ดให้ทำงานได้ แต่ยังต้องทำให้ระบบ เสถียร, เร็ว, และ ตรวจสอบปัญหาได้ทันเวลา ด้วย เพราะเมื่อเว็บช้าหรือพังขึ้นมา สาเหตุมักไม่ใช่ “บั๊กเดียว” แต่เป็นลูกโซ่ของหลายเหตุการณ์ที่เกิดต่อเนื่องกัน
แนวคิด Observability จึงเข้ามามีบทบาทสำคัญ เพราะช่วยให้เรามองเห็นสิ่งที่เกิดขึ้นจริงภายในระบบ จากนั้นจึงเชื่อมโยงข้อมูลเพื่อหาต้นตอของปัญหาได้แม่นยำขึ้น แทนที่จะอาศัยการคาดเดา
หัวใจของ Observability มีอยู่ 3 เสาหลัก ได้แก่ Logs, Metrics และ Traces ซึ่งแต่ละอย่างตอบคำถามคนละแบบ และเมื่อใช้ร่วมกันจะทรงพลังมาก
1) Logs: เรื่องเล่าแบบละเอียดของระบบ
Logs คือข้อมูลเหตุการณ์ที่เกิดขึ้นในระบบแบบละเอียด เป็นเหมือนบันทึกที่เล่าว่า ณ เวลาหนึ่งมีอะไรเกิดขึ้นบ้าง แต่ log ที่ดีไม่ใช่แค่การ print ข้อความออกมาเท่านั้น หากต้องสามารถ ค้นหาได้, กรองได้, และ เชื่อมโยงกับข้อมูลอื่นได้
แนวทางที่ควรทำคือเปลี่ยน log ให้เป็น structured log เช่นรูปแบบ JSON เพื่อให้ระบบค้นหาและวิเคราะห์ได้ง่าย โดยควรมีฟิลด์สำคัญอย่างน้อยดังนี้
timestamplevelservicerouteuserId(ถ้ามี)requestIdlatencyMserrorCode
การมีข้อมูลเหล่านี้จะช่วยให้เวลาระบบมีปัญหา เราไล่เหตุการณ์ย้อนหลังได้เร็วขึ้นมาก อย่างไรก็ตาม สิ่งสำคัญที่ต้องระวังคือ อย่าบันทึกข้อมูลลับ เช่น password, token หรือข้อมูลอ่อนไหวทางการเงินลงใน log เด็ดขาด
2) Metrics: สัญญาณชีพที่บอกภาพรวมของระบบ
หาก Logs เปรียบเหมือนรายละเอียดรายเหตุการณ์ Metrics ก็เปรียบเหมือน “สัญญาณชีพ” ของระบบที่ช่วยให้เห็นภาพรวมได้ชัดเจน ว่าระบบกำลังอยู่ในสภาวะปกติหรือเริ่มมีแนวโน้มผิดปกติ
Metrics มีประโยชน์มากในเรื่องการทำ dashboard และการตั้ง alert เพื่อให้ทีมรู้ปัญหาก่อนที่ลูกค้าจะเริ่มร้องเรียน โดยหลักที่นิยมใช้คือ Golden Signals ได้แก่
- Latency: ระบบตอบสนองช้าแค่ไหน
- Traffic: มีปริมาณการใช้งานเท่าไร
- Errors: เกิดข้อผิดพลาดมากน้อยเพียงใด
- Saturation: ทรัพยากรเริ่มตึงหรือใกล้เต็มหรือไม่
ตัวอย่าง metrics ที่ควรมีในระบบเว็บ เช่น
- p95 latency แยกตาม endpoint
- error rate ระดับ 5xx
- CPU และ memory
- DB connection pool
- queue depth
ข้อควรจำที่สำคัญมากคือ ค่าเฉลี่ยหลอกได้เก่ง เพราะบางครั้งค่าเฉลี่ยดูปกติ แต่ผู้ใช้บางส่วนอาจเจอประสบการณ์ที่แย่มาก ดังนั้นจึงควรดู percentiles เช่น p95 หรือ p99 เป็นหลัก มากกว่าดู average เพียงอย่างเดียว
3) Traces: แผนที่การเดินทางของ request
Traces ช่วยตอบคำถามที่ว่า request หนึ่งครั้งเดินทางผ่านอะไรบ้าง และไปช้าตรงจุดไหน โดยเฉพาะในระบบที่มีหลาย service หรือมีการเรียกต่อกันหลายชั้น เช่น
API → Database → Cache → External Service
เมื่อมี trace ที่ดี เราจะเห็นได้ทันทีว่า request ที่ช้าหรือพังนั้นเกิดคอขวดที่ขั้นตอนใด เช่น ช้าเพราะ query database, รอ external API นาน, หรือเสียเวลาจาก retry ซ้ำหลายรอบ
สิ่งที่จะทำให้ trace ใช้งานได้จริงคือการ propagate ค่า traceId หรือ requestId ข้ามทุก service เพื่อให้ข้อมูลตลอดเส้นทางถูกร้อยเรียงเป็นเรื่องเดียวกัน
Logs, Metrics, Traces ต่างกันอย่างไร
เพื่อให้จำง่าย สามารถสรุปหน้าที่ของทั้ง 3 อย่างได้ดังนี้
- Logs ตอบว่า: “เกิดอะไรขึ้น”
- Metrics ตอบว่า: “เกิดมากแค่ไหน และแย่แค่ไหน”
- Traces ตอบว่า: “มันช้าเพราะตรงไหน”
สูตรลับที่ทำให้ Observability ทรงพลังจริง คือ เชื่อมทั้ง 3 อย่างเข้าด้วยกันด้วย ID เดียวกัน เช่น traceId และ requestId หากทุก log ผูกกับ trace เดียวกันได้ เวลามีปัญหาจะไล่เหตุการณ์ได้ในไม่กี่นาที
ตัวอย่างสถานการณ์จริง: ลูกค้าบ่นว่าหน้า checkout ช้า
ลองนึกภาพว่าลูกค้าร้องเรียนว่าเว็บช้าตอนกดจ่ายเงินนานเกือบ 1 นาที วิธีที่มีประสิทธิภาพในการหาสาเหตุอาจเป็นลำดับแบบนี้
- เปิด dashboard metrics แล้วพบว่า
p95ของ endpoint/checkoutพุ่งสูงในช่วงเวลาเดียวกัน - คลิกจากกราฟไปดู traces ของช่วงเวลานั้น และ filter เฉพาะ
/checkout - พบว่า span ของ
payment-gatewayใช้เวลานานถึง 45 วินาทีในบาง request - เปิด log ของ service ฝั่ง payment โดยใช้
traceIdเดียวกัน - พบว่า service มีการ retry ซ้ำ 6 ครั้งเพราะ timeout
- สรุปได้ว่าปัญหามาจากการตั้ง timeout ต่ำเกินไป ไม่มี circuit breaker และ retry ไม่มี backoff
กรณีนี้สะท้อนให้เห็นว่าปัญหาเว็บช้าไม่ได้เกิดจากจุดเดียว แต่เกิดจากหลายองค์ประกอบที่หนุนกันจนกลายเป็นอาการใหญ่ และถ้าไม่มี Observability ที่เชื่อมกันครบ ก็แทบเป็นไปไม่ได้เลยที่จะหาสาเหตุได้เร็ว
เรื่องที่หลายทีมมักพลาด
หนึ่งในความเข้าใจผิดที่พบบ่อยคือการคิดว่า retry ยิ่งมากยิ่งดี แต่ในความเป็นจริง retry ที่ออกแบบไม่ดีอาจทำให้ระบบล่มเร็วขึ้น เพราะมันเพิ่มโหลดซ้ำ ๆ ในช่วงที่ปลายทางกำลังมีปัญหาอยู่แล้ว
นอกจากนี้ยังมีจุดพลาดอื่น ๆ ที่ควรระวัง เช่น
- ไม่ใส่ correlation ID ตั้งแต่ edge เช่น CDN หรือ Load Balancer
- ตั้งชื่อ route หรือ span ไม่สม่ำเสมอ
- log เป็นข้อความยาวล้วน ทำให้ค้นหายาก
- ไม่แยกประเภท error ให้ชัดเจน เช่น 4xx, 5xx และ timeout
- ปล่อยให้ข้อมูลของ production กับ staging ปนกัน
รายละเอียดเล็ก ๆ เหล่านี้มีผลมากต่อความเร็วในการสืบหาปัญหา
เทคนิคที่ช่วยให้แก้ปัญหาไวขึ้นหลายเท่า
หากต้องการทำ Observability ให้เกิดผลจริงในงานประจำวัน ควรเริ่มจากแนวทางต่อไปนี้
- ใส่ correlation ID ตั้งแต่ต้นทาง และส่งต่อทุก hop
- ตั้งชื่อ route และ span ให้เป็นมาตรฐาน เช่น
HTTP GET /users/:id - แยกหมวดหมู่ error ให้ชัดเจน
- ทำ smart trace sampling เช่น เก็บ 100% สำหรับ error หรือ slow requests และเก็บบางส่วนสำหรับ request ปกติ
- ใช้ structured logs แบบ
key=valueหรือ JSON - ตั้ง SLO ที่อ่านแล้วเข้าใจง่าย เช่น
/checkout p95 < 800ms - ผูก SLO เข้ากับ alert และ burn rate เพื่อให้รู้ว่าระบบกำลังเสี่ยงผิดเป้าหรือไม่
แนวทางเหล่านี้จะช่วยให้ทีมลดเวลาจาก “พบปัญหา” ไปสู่ “เจอต้นเหตุ” ได้อย่างมาก
เครื่องมือยอดนิยมที่เริ่มใช้ได้ไม่ยาก
สำหรับทีมที่อยากเริ่มทำ Observability ปัจจุบันมีเครื่องมือที่ค่อนข้างเป็นมาตรฐานและคุ้มค่าหลายตัว เช่น
- OpenTelemetry สำหรับเก็บ log, metric และ trace ในรูปแบบมาตรฐาน
- Prometheus + Grafana สำหรับ metrics และ dashboard
- Loki หรือ Elasticsearch สำหรับจัดการ logs
- Jaeger หรือ Tempo สำหรับ traces
ถ้าเป็นทีมเล็กและอยากเริ่มให้เร็วที่สุด แนะนำให้เริ่มจาก metrics ก่อน เพราะใช้ทำ alert ได้ทันที จากนั้นจึงเพิ่ม trace เพื่อหาคอขวด และค่อยทำ logs ให้ structured อย่างครบถ้วน
เป้าหมายของ Observability ไม่ใช่เก็บทุกอย่าง
สิ่งสำคัญที่สุดคือ เราไม่ได้ทำ Observability เพื่อเก็บข้อมูลให้เยอะที่สุด แต่ทำเพื่อให้ ตอบคำถามสำคัญได้เร็วที่สุด เช่น
- ระบบช้าจริงไหม
- ช้าตรง endpoint ไหน
- ช้าเพราะ service ไหน
- มี error แบบไหนเพิ่มขึ้นผิดปกติ
- ปัญหาเกิดเฉพาะ production หรือทุก environment
ถ้าข้อมูลที่เก็บช่วยตอบคำถามเหล่านี้ได้เร็ว แสดงว่า Observability ของเรากำลังทำงานอย่างมีประสิทธิภาพ
สรุป
Observability คือการทำให้ทีมมองเห็นความจริงของระบบผ่าน 3 เสาหลัก ได้แก่ Logs, Metrics และ Traces โดยแต่ละส่วนมีหน้าที่ต่างกัน แต่จะยิ่งมีพลังเมื่อเชื่อมโยงกันด้วย traceId หรือ requestId เดียวกัน
เมื่อมีข้อมูลครบและออกแบบอย่างถูกต้อง การรับมือกับปัญหาเว็บช้าหรือเว็บล่มจะเปลี่ยนจากการเดาสุ่มไปสู่การวิเคราะห์อย่างมีหลักฐาน ช่วยให้ทีมแก้ปัญหาได้เร็วขึ้น แม่นขึ้น และลดผลกระทบต่อผู้ใช้งานได้อย่างชัดเจน