วางระบบ Log และ Audit Trail บนเว็บไซต์ให้ตามรอยปัญหาได้จริง
การมี Log จำนวนมากไม่ได้ช่วยแก้ปัญหา หากไม่มีโครงสร้างที่ดีและไม่สามารถเชื่อมโยงเหตุการณ์ข้ามระบบได้ บทความนี้สรุปแนวทางทำ Log และ Audit Trail แบบใช้งานได้จริงสำหรับการ Debug, Incident, Security และ Compliance.
วางระบบ Log และ Audit Trail บนเว็บไซต์ให้ตามรอยปัญหาได้จริง
หลายองค์กรมีข้อมูล Log อยู่จำนวนมาก แต่เมื่อเกิดปัญหาในระบบ production กลับไม่สามารถตามรอยสาเหตุได้จริง สาเหตุสำคัญมักไม่ใช่เพราะ Log น้อยเกินไป แต่เป็นเพราะ Log ไม่มีโครงสร้าง ไม่มีจุดเชื่อมโยงระหว่างเหตุการณ์ และไม่ได้ออกแบบมาเพื่อรองรับการวิเคราะห์ปัญหาอย่างเป็นระบบ
แนวทางการทำ Log และ Audit Trail ที่ดี จะช่วยให้ทีมสามารถตรวจสอบปัญหาเชิงเทคนิค วิเคราะห์ incident ติดตามเหตุการณ์ด้านความปลอดภัย และตอบโจทย์ด้าน compliance ได้พร้อมกัน
1) แยกให้ชัดระหว่าง Log และ Audit Trail
สิ่งแรกที่ต้องทำคือทำความเข้าใจว่า Log และ Audit Trail มีหน้าที่ต่างกัน
Log ใช้บันทึกเหตุการณ์เชิงเทคนิค เช่น
- request error
- timeout
- query ช้า
- service ล่ม
ส่วน Audit Trail ใช้บันทึกการกระทำที่มีผลต่อข้อมูลหรือสิทธิ์ เช่น
- การสร้างคำสั่งซื้อ
- การเปลี่ยนสิทธิ์ผู้ใช้
- การลบหรือแก้ไขข้อมูลสำคัญ
หลักคิดแบบง่ายคือ
- Log มีไว้เพื่อตามปัญหา
- Audit Trail มีไว้พิสูจน์ว่าใครทำอะไร เมื่อไหร่ และเกิดผลอย่างไร
เมื่อแยกสองสิ่งนี้ชัดเจน การออกแบบระบบจะตอบโจทย์มากขึ้น และไม่ปนกันจนใช้งานยากในภายหลัง
2) ออกแบบ Log ให้เป็น Structured Logging
Log ที่ดีควรอ่านง่าย ค้นง่าย และนำไปประมวลผลต่อได้สะดวก วิธีที่แนะนำคือใช้ Structured Logging ในรูปแบบ JSON ทุกบรรทัด แทนการเขียนเป็นข้อความยาวแบบอิสระ
ฟิลด์สำคัญที่ควรมีใน Log ได้แก่
timestampในรูปแบบ ISO-8601 พร้อม timezonelevelเช่น DEBUG, INFO, WARN, ERRORserviceหรือชื่อ applicationenvironmentเช่น prod, stage, devversionหรือ git commitmessageแบบสั้นและชัดเจนevent_nameเช่นpayment.charge_failedcorrelation_idสำหรับเชื่อมหลายบริการrequest_idสำหรับระบุแต่ละ requestuser_idในรูปแบบที่ไม่เปิดเผยข้อมูลส่วนตัวตรงๆipโดยอาจพิจารณา mask บางส่วนlatency_mserror_codestacktraceเฉพาะกรณี error
การมีฟิลด์มาตรฐานตั้งแต่ต้น จะช่วยให้ค้นหาและวิเคราะห์เหตุการณ์ได้เร็วขึ้นมาก โดยเฉพาะเมื่อระบบเริ่มมีหลายบริการและปริมาณข้อมูลเพิ่มขึ้น
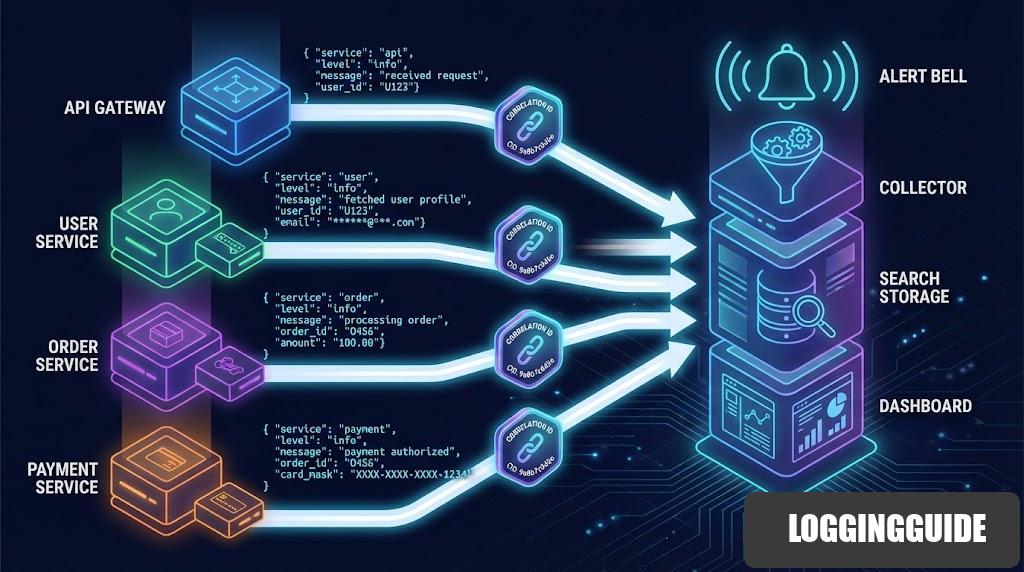
3) ใช้ Correlation ID เพื่อเชื่อมเหตุการณ์ทั้งระบบ
หัวใจของการตามรอยปัญหาในระบบสมัยใหม่คือ Correlation ID เพราะช่วยให้ทีมมองเห็นเส้นทางของคำขอหนึ่งรายการที่ไหลผ่านหลาย service ได้ครบถ้วน
แนวทางการใช้งานที่เหมาะสมคือ
- รับ
correlation_idจาก request header ถ้ามี เช่นX-Correlation-Id - หากไม่มี ให้ระบบสร้างใหม่ เช่น UUID
- ส่ง
correlation_idกลับไปใน response header - ส่งต่อค่าเดียวกันไปยังทุก downstream call เช่น HTTP, gRPC หรือ queue message
- บันทึก
correlation_idลงในทุก Log ที่เกี่ยวข้อง
ตัวอย่างเส้นทางการไหลของเหตุการณ์อาจเป็น Browser -> API Gateway -> User Service -> Order Service -> Payment Service
หากทุกจุดใช้ correlation_id เดียวกัน ทีมจะสามารถค้นหาเหตุการณ์ทั้งสายได้จากรหัสเดียว ไม่ต้องไล่เดาจากเวลาและข้อความ Log แบบกระจัดกระจาย
4) Log เฉพาะจุดสำคัญ ไม่ใช่ Log ทุกอย่าง
หนึ่งในความเข้าใจผิดที่พบบ่อยคือคิดว่ายิ่ง Log มากยิ่งดี แต่ในความเป็นจริง Log ที่มากเกินไปและไม่มีจุดหมาย จะทำให้ค้นหาข้อมูลยากขึ้นและเพิ่มต้นทุนการจัดเก็บโดยไม่จำเป็น
จุดขั้นต่ำที่ควรบันทึก ได้แก่
- จุดเริ่มต้นของ request แบบย่อ
- จุดสิ้นสุดของ request พร้อม status code และ latency
- เหตุการณ์ error ทุกครั้ง พร้อมสาเหตุและรหัสข้อผิดพลาด
- การเรียก external dependency เช่น payment, email, storage
- business milestone สำคัญ เช่น
order_created,payment_success - เหตุการณ์ด้านความปลอดภัย เช่น rate limit หรือ auth failure
สิ่งที่ควรหลีกเลี่ยงอย่างยิ่งคือ
- การ Log request/response body เต็มโดยไม่มีเหตุผล
- การบันทึกข้อมูลบัตรเครดิต รหัสผ่าน token หรือ OTP
หลักคิดสำคัญคือ Log เท่าที่จำเป็นต่อการวิเคราะห์ ไม่ใช่เก็บทุกอย่างแบบไร้การคัดกรอง
5) ทำ Audit Trail ให้เชื่อถือได้และแก้ไขย้อนหลังได้ยาก
Audit Trail ที่ดีต้องไม่ใช่แค่มีข้อมูลครบ แต่ต้องน่าเชื่อถือเพียงพอที่จะใช้ตรวจสอบย้อนหลังได้จริง
ฟิลด์ที่ควรมีใน Audit Record ได้แก่
actor_typeเช่น user, admin, systemactor_idactionเช่นupdate_role,delete_orderresource_typeและresource_idresultเช่น success หรือ failreasonในกรณีมีสาเหตุสำคัญ- ค่า
before/afterเฉพาะฟิลด์ที่จำเป็น timestampsourceเช่น web, api, batchcorrelation_idเพื่อเชื่อมกับ Log ฝั่งเทคนิค
เพื่อป้องกันการแก้ไขย้อนหลัง ควรใช้แนวทางต่อไปนี้
- แยก storage ของ audit ออกจากฐานข้อมูลหลัก
- กำหนดสิทธิ์เป็นแบบ append-only เขียนเพิ่มได้แต่แก้หรือลบไม่ได้
- มีนโยบาย retention และ backup ที่ชัดเจน
Audit Trail ที่ดีจะช่วยเพิ่มความมั่นใจทั้งในมุมการสอบสวนเหตุการณ์และข้อกำหนดด้านกฎหมายหรือมาตรฐานองค์กร
6) รวม Log เข้าสู่ศูนย์กลางเพื่อค้นหาได้จากที่เดียว
เมื่อระบบมีหลายเครื่องหรือหลาย service การเก็บ Log แยกตามเครื่องจะทำให้การสืบค้นยุ่งยากมาก ควรออกแบบเป็น Centralized Logging ตั้งแต่ต้น
องค์ประกอบที่นิยมใช้ ได้แก่
- Application ส่ง Log ออกทาง stdout หรือ file
- Agent หรือ Collector เช่น Fluent Bit, Vector หรือ Filebeat
- ระบบจัดเก็บและค้นหา เช่น Elasticsearch, OpenSearch หรือ Loki
- ระบบ dashboard และ query เช่น Kibana หรือ Grafana
ข้อควรระวังคือควรติด tag สำคัญตั้งแต่แรก เช่น
- service
- environment
- region
นอกจากนี้ควรกำหนด retention ให้เหมาะสม เช่น
- ERROR เก็บไว้นานกว่า INFO
- ข้อมูลบางประเภทบีบอัดเพื่อลดต้นทุน
การรวมศูนย์ที่ดีทำให้ทีมไม่ต้องเสียเวลาสลับเข้าออกหลายเครื่องเพื่อไล่ดูข้อมูลทีละจุด
7) ตั้ง Alert ให้เตือนเฉพาะเรื่องที่ควรสนใจจริง
Alert ที่ดีไม่ใช่การเตือนทุก error แต่เป็นการเตือนเมื่อมีผลกระทบต่อผู้ใช้หรือธุรกิจจริง
ตัวอย่าง Alert ที่ควรมี เช่น
- อัตรา 5xx เกิน threshold ต่อเนื่อง 5 นาที
- p95 latency สูงเกินเป้าหมาย
- อัตรา payment failed เพิ่มผิดปกติ
- จำนวน login failed พุ่งสูง อาจบ่งชี้การโจมตีแบบ brute force
- queue lag เกินค่าที่กำหนด
- disk หรือ storage ของระบบ Log ใกล้เต็ม
เพื่อให้ Alert มีคุณภาพมากขึ้น ควร
- ใช้หลายสัญญาณประกอบกัน เช่น error rate ร่วมกับ traffic
- แนบ runbook หรือ query ตัวอย่างให้ทีมเปิดตรวจสอบต่อได้ทันที
ผลลัพธ์คือทีมจะได้รับการแจ้งเตือนที่มีความหมาย ลด false alarm และตอบสนองต่อเหตุการณ์สำคัญได้เร็วขึ้น
8) เชื่อม Log เข้ากับ Metrics และ Tracing
การสังเกตระบบอย่างครบถ้วนไม่ควรพึ่ง Log อย่างเดียว เพราะแต่ละเครื่องมือมีหน้าที่ต่างกัน
- Log ตอบคำถามว่าเกิดอะไรขึ้น
- Metrics ตอบว่าเกิดบ่อยแค่ไหน และส่งผลมากน้อยเพียงใด
- Tracing ตอบว่าความช้าหรือปัญหาเกิดตรงไหนในลำดับการทำงาน
หากสามารถเชื่อม correlation_id เข้ากับ trace_id ได้ จะช่วยให้เห็นภาพทั้งระดับเหตุการณ์และระดับประสิทธิภาพในมุมเดียวกัน โดยเฉพาะเมื่อใช้เครื่องมืออย่าง OpenTelemetry
9) คำนึงถึงข้อมูลส่วนตัวและกฎหมายตั้งแต่วันแรก
การทำ Log และ Audit Trail ที่ดีต้องไม่ละเลยเรื่อง privacy เพราะข้อมูลที่บันทึกไว้มีความเสี่ยงสูงหากหลุดหรือเข้าถึงโดยไม่เหมาะสม
แนวปฏิบัติที่แนะนำ ได้แก่
- ใช้ allowlist ระบุชัดว่าฟิลด์ใด Log ได้
- mask หรือ redact ข้อมูลสำคัญ เช่น email, phone, address
- ห้าม Log access token, refresh token หรือ session cookie
- กำหนด retention ตามความจำเป็นจริง
- จำกัดสิทธิ์การเข้าถึง Log และ Audit Trail
- ทำ access audit ซ้ำอีกชั้นสำหรับผู้ที่เข้าดูข้อมูลเหล่านี้
การออกแบบโดยยึดหลัก Privacy by Design จะช่วยลดความเสี่ยงทั้งด้านความปลอดภัยและข้อกฎหมายในระยะยาว
10) ทดสอบด้วยเหตุการณ์จำลองเพื่อพิสูจน์ว่าตามรอยได้จริง
ต่อให้วางโครงสร้างมาดีแค่ไหน หากไม่ทดสอบ ก็อาจพบว่าเมื่อเกิด incident จริงกลับมีข้อมูลไม่ครบ การทำเหตุการณ์จำลองจึงเป็นวิธีตรวจสอบที่สำคัญมาก
ตัวอย่างการทดสอบง่ายๆ คือ
- ยิงคำสั่งซื้อเข้าระบบ 1 รายการ
- จด
correlation_idจาก response header - ค้นหาในระบบรวมศูนย์ด้วยรหัสนี้
- ตรวจว่ามีข้อมูลครบตั้งแต่ API รับ request ไปจนถึงการสร้าง order การเรียก payment และผลลัพธ์สุดท้าย
หากพบว่าข้อมูลขาดช่วงตรงไหน จุดนั้นคือสิ่งที่ต้องกลับไปเพิ่มการส่งต่อ ID หรือเพิ่ม Log ในตำแหน่งที่จำเป็น
สรุป
การทำระบบ Log และ Audit Trail ให้มีประสิทธิภาพ ไม่ได้หมายถึงการเก็บข้อมูลให้มากที่สุด แต่คือการออกแบบให้ข้อมูลมีโครงสร้าง ค้นหาได้ เชื่อมโยงกันได้ และเชื่อถือได้
หัวใจสำคัญมีอยู่ไม่กี่ข้อ ได้แก่
- แยกบทบาทของ Log และ Audit Trail ให้ชัด
- ใช้ Structured Logging
- ส่ง Correlation ID ให้ไหลทั้งระบบ
- Log เฉพาะจุดสำคัญ
- ทำ Audit Trail แบบแก้ไขย้อนหลังได้ยาก
- รวม Log ไว้ศูนย์กลาง
- ตั้ง Alert อย่างพอดีและมีคุณภาพ
- เชื่อมกับ Metrics และ Tracing
- ระวังข้อมูลส่วนตัวตั้งแต่ต้น
- ทดสอบด้วยเหตุการณ์จำลองเสมอ
หากทำได้ครบ ระบบ production ที่เคยทำให้ทีมต้องเดาและเสียเวลาหลายชั่วโมง จะกลายเป็นระบบที่สามารถค้นหาสาเหตุได้อย่างรวดเร็วและแม่นยำภายในไม่กี่นาที